글로벌 B2B SaaS 아키텍처 설계 시 필수로 고려해야 할 데이터 격리 전략과 테넌트 오염 방지 방안을 담은 실무 가이드입니다. AWS 및 RDS를 활용한 비용 효율적 멀티테넌트 설계법을 분석합니다.
서론: 엔터프라이즈급 SaaS의 데이터 격리 고충
글로벌 B2B SaaS 플랫폼을 운영하며 수천 명의 고객 데이터를 관리하는 엔터프라이즈급 기업의 보안 감사(Security Audit) 현장은 언제나 긴장감이 흐릅니다. 최근 한 금융 서비스 기업은 자사의 민감한 고객 데이터를 위탁하려는 조건으로, 단순한 암호화를 넘어선 물리적 수준의 데이터 격리(Data Isolation) 증명과 테넌트 오염(Tenant Pollution) 방지 대책을 요구했습니다. 클라우드 기반의 공유 리소스 아키텍처를 사용하는 입장에서, 이는 단순한 기술적 문제를 넘어 계약의 성사 여부를 결정짓는 비즈니스적 장벽이었습니다.
대규모 트래픽을 처리하기 위해 도입한 데이터베이스 샤딩(Database Sharding) 구조와 AWS Lambda 기반의 서버리스 아키텍처는 확장성 면에서는 훌륭했으나, 각 테넌트(Tenant) 간의 경계가 모호해질 경우 발생하는 보안 리스크는 관리자의 큰 고민거리였습니다. 특히 AWS Organizations와 IAM 정책을 통해 구축한 논리적 격리(Logical Isolation)가 실제 애플리케이션 레이어의 코드 오류로 인해 무너지는 순간, 단 한 명의 테넌트가 타 고객의 데이터를 조회하는 사고는 기업의 신뢰도를 회복 불가능한 수준으로 추락시킬 수 있습니다.
이 글에서는 엔터프라이즈급 SaaS 아키텍처를 설계할 때 직면하는 데이터 격리의 기술적 난제들을 분석하고, 비용 효율성을 유지하면서도 보안 컴플라이언스(Compliance)를 충족할 수 있는 최적의 아키텍처 전략을 다루고자 합니다. 또한 AWS RDS Proxy를 활용한 커넥션 관리나 PostgreSQL의 RLS(Row-Level Security) 같은 구체적인 기술적 해결책을 제시하여, 실무에서 바로 적용 가능한 가이드라인을 제공합니다.
1. 멀티테넌트 아키텍처의 설계 철학과 계층별 격리 메커니즘
1.1 기술의 탄생 배경과 설계 철학
멀티테넌트 아키텍처(Multi-tenant Architecture)의 핵심은 '자원 공유를 통한 비용 최적화'와 '독립적 운영을 통한 보안성 확보'라는 양립하기 어려운 두 가치를 동시에 달성하는 데 있습니다. 초기 SaaS 모델은 단순한 데이터베이스(Database) 수준의 공유에서 시작되었으나, 기업용(Enterprise) 시장이 확대됨에 따라 격리 수준에 대한 요구사항은 점차 고도화되었습니다.
설계 철학은 크게 세 가지 패턴으로 분류됩니다.
- Silo 패턴: 각 테넌트마다 독립적인 인프라(VPC, EC2, RDS 등)를 할당하는 방식으로, 물리적 격리가 완벽하여 보안성은 극대화되나 테넌트 증가에 따른 인프라 관리 비용과 리소스 복잡성이 기하급수적으로 증가합니다.
- Pool 패턴: 모든 테넌트가 동일한 인프라와 데이터베이스를 공유하며 테넌트 식별자(Tenant ID)로만 데이터를 구분하는 방식입니다. 비용 효율은 압도적이지만, 단 한 번의 쿼리 오류로도 대규모 데이터 유출이 발생할 수 있는 위험을 안고 있습니다.
- Bridge 패턴: 핵심 로직은 공유하되 데이터베이스나 특정 레이어만 분리하는 하이브리드 접근법입니다.

💡 클라우드메트릭 비평 및 인사이트
엔터프라이즈 SaaS 설계 시 모든 고객에게 동일한 격리 수준을 적용하는 것은 비용 낭비입니다. 표준 고객에게는 Pool 패턴을, 높은 보안 요구사항을 가진 VIP 고객에게는 Silo 패턴을 적용하는 'Tiered Isolation' 전략이 AWS Organizations 기반의 멀티 계정 전략과 결합될 때 가장 경제적인 비용 최적화를 달성할 수 있습니다.
1.2 핵심 아키텍처와 데이터 액세스 제어 원리
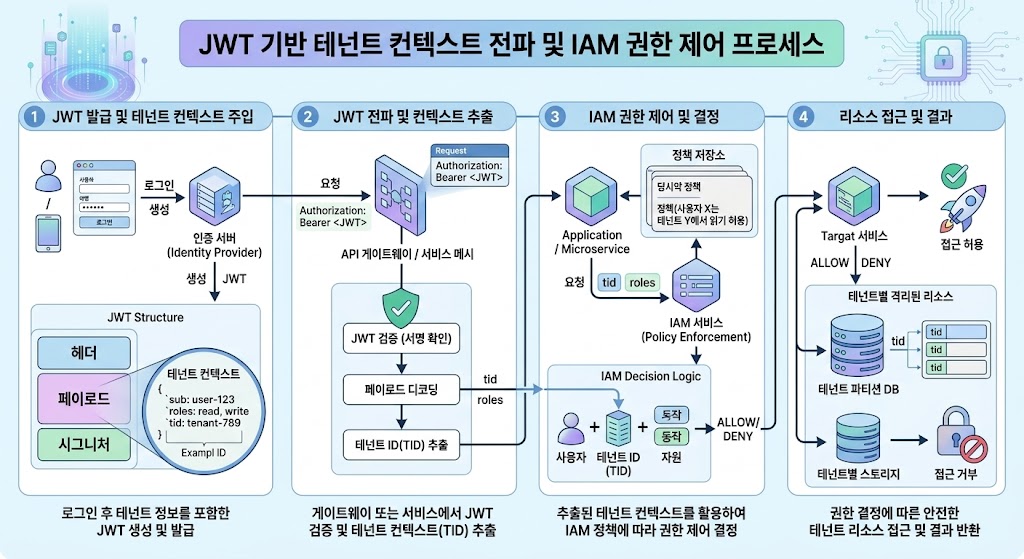
현대적인 고성능 SaaS 아키텍처는 4계층(Presentation, Business, Data Access, Storage) 구조를 따르며, 각 계층 사이에는 명확한 테넌트 컨텍스트(Tenant Context) 전달 메커니즘이 존재해야 합니다. 사용자가 API Gateway를 통해 요청을 보내면, Lambda@Edge 또는 Authorizer 단계에서 JWT(JSON Web Token) 내부의 Tenant ID를 추출하여 요청의 생명주기 동안 전역적인 컨텍스트로 유지해야 합니다.
데이터 액세스 계층(Data Access Layer)에서의 핵심은 역할 기반 접근 제어(RBAC)를 데이터베이스 수준까지 확장하는 것입니다. 예를 들어, AWS STS(Security Token Service)를 활용하여 요청한 테넌트의 권한에만 접근 가능한 임시 자격 증명을 생성하고, 이를 통해 Amazon S3나 DynamoDB에 접근하게 함으로써 애플리케이션 코드의 실수를 인프라 레이어에서 차단하는 심층 방어(Defense in Depth) 전략을 구현할 수 있습니다.
💡 클라우드메트릭 비평 및 인사이트
Data Access Layer에서 단순한WHERE tenant_id = ?쿼리에 의존하는 것은 매우 위험합니다. 반드시 Row-Level Security(RLS) 기능을 지원하는 PostgreSQL 등을 활용하여, 데이터베이스 엔진 자체가 쿼리 컨텍스트를 검증하도록 강제해야 테넌트 오염(Tenant Pollution)을 근본적으로 방지할 수 있습니다.
2. 실무 적용을 위한 데이터 격리 및 식별자 관리 전략
2.1 테넌트 식별자(Tenant ID)의 설계와 보안 전파
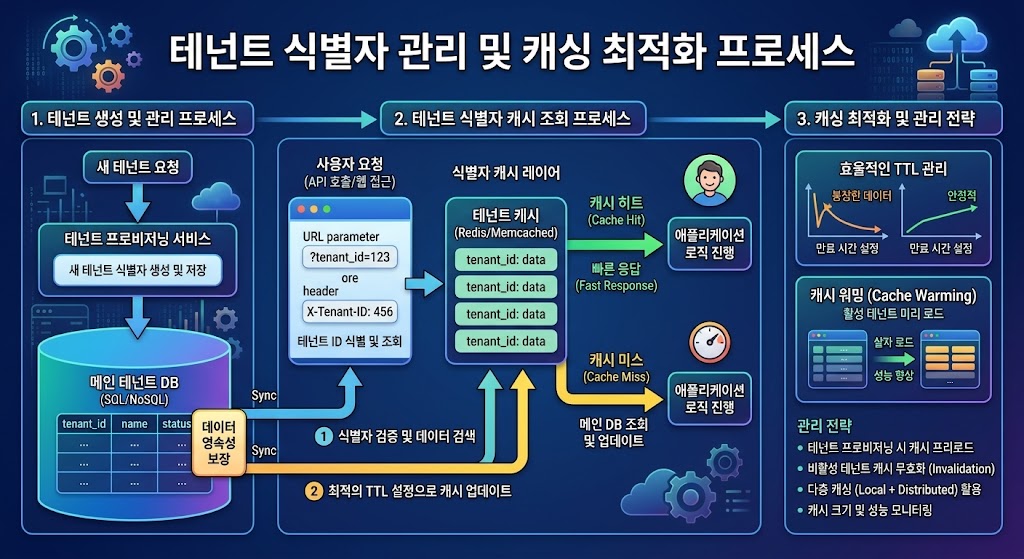
테넌트 식별자(Tenant ID)는 멀티테넌트 시스템의 혈맥과 같습니다. 이 식별자가 어떻게 생성되고 전달되느냐에 따라 시스템 전체의 확장성과 보안성이 결정됩니다. 실무적으로 가장 권장되는 방식은 UUID(Universally Unique Identifier) v4 또는 Snowflake ID를 사용하는 것입니다. 단순한 순차적 정수(Auto-increment Integer)를 사용할 경우, 공격자가 예측 가능한 패턴을 통해 다른 테넌트의 데이터를 추측하는 ID Enumeration 공격에 취약해질 수 있기 때문입니다.
전파 전략 측면에서는 JWT(JSON Web Token) 내에 tenant_id를 Custom Claim으로 포함시키는 것이 가장 효율적입니다. 이렇게 하면 API Gateway나 Application Load Balancer(ALB) 수준에서 별도의 데이터베이스 조회 없이도 요청의 주체를 식별할 수 있습니다. 또한, Redis나 AWS ElastiCache를 활용하여 테넌트별 설정값(Feature Flags, Quota 등)을 캐싱하면, 매 요청마다 테넌트 메타데이터를 조회하는 오버헤드를 줄여 응답 속도를 밀리초(ms) 단위로 유지할 수 있습니다.
💡 클라우드메트릭 비평 및 인사이트
Snowflake ID는 시간 순서로 정렬 가능하다는 장점이 있어 DynamoDB의 Partition Key 설계 시 데이터 분포를 균일하게 만드는 데 유리합니다. 반면, 단순 UUID는 분포는 우수하지만 인덱스 크기를 키우고 B-Tree 구조의 삽입 성능을 저해할 수 있으므로, 쓰기 작업이 빈번한 환경에서는 정렬 가능한 고유 식별자 사용을 강력히 권장합니다.
2.2 데이터베이스 격리 구현 방법론과 연결 관리
데이터베이스 레이어에서의 격리는 비용과 보안의 최전선입니다. 가장 구현이 쉬운 방식은 하나의 테이블에 tenant_id 컬럼을 추가하는 논리적 격리입니다. 이는 운영 효율이 매우 높지만, 쿼리 작성 실수나 JOIN 연산 오류로 인한 데이터 혼입 가능성이 존재합니다. 이를 보완하기 위해 PostgreSQL의 Row-Level Security(RLS)를 적용하여, 세션 수준에서 특정 tenant_id만 보이도록 강제하는 기법이 실무에서 널리 사용됩니다.
더 높은 수준의 격리가 필요한 경우에는 스키마(Schema) 기반 격리 또는 데이터베이스 인스턴스 기반 격리를 고려해야 합니다. 스키마 기반 방식은 하나의 인스턴스 내에서 논리적으로 분리된 영역을 제공하여 PostgreSQL의 장점을 활용하면서도 어느 정도의 격리를 보장합니다. 하지만 AWS Lambda와 같은 서버리스 환경에서 수천 개의 테넌트별로 별도의 커넥션을 생성할 경우, 커넥션 고갈(Connection Exhaustion) 문제가 발생할 수 있습니다. 이를 해결하기 위해 Amazon RDS Proxy를 도입하여 Connection Pooling을 관리함으로써, 애플리케이션 가용성을 높이고 데이터베이스의 부하를 효율적으로 제어해야 합니다.

💡 클라우드메트릭 비평 및 인사이트
RDS Proxy 도입 시 반드시 고려해야 할 점은 비용과 지연 시간(Latency)입니다. 단순한 읽기 위주의 워크로드라면 Proxy를 통한 오버헤드가 더 클 수 있으므로, 실제 트래픽 패턴을 분석하여 Connection Pooling이 절실한 시점에 도입하는 전략적 판단이 필요합니다.
3. 성능 비교와 차세대 멀티테넌트 기술 분석
3.1 데이터베이스 스택별 성능 및 격리 특성 비교
멀티테넌트 아키텍처의 성패는 선택한 데이터베이스 스택의 특성을 얼마나 잘 이해하느냐에 달려 있습니다. 아래 표는 엔터프라이즈 환경에서 가장 많이 사용되는 솔루션들의 특성을 비교한 것입니다.
| 비교 항목 | PostgreSQL (RLS 적용) | Amazon DynamoDB | MongoDB (Atlas) | Firebase Firestore |
|---|---|---|---|---|
| 격리 수준 | 높음 (논리적 강제) | 중간 (Partition Key 의존) | 중간 (Document 기반) | 높음 (Security Rules) |
| 확장성 (Scalability) | 중간 (Vertical/Sharding) | 매우 높음 (Horizontal) | 높음 (Sharding) | 매우 높음 (Serverless) |
| 복잡한 쿼리 (JOIN) | 매우 우수 | 매우 제한적 | 우수 | 거의 불가능 |
| 운영 비용 (Cost) | 중간 (Instance 기반) | 사용량 기반 (Pay-per-request) | 중간 (Cluster 기반) | 매우 낮음 (Serverless) |
PostgreSQL은 복잡한 관계형 데이터와 강력한 RLS를 통한 보안이 필수적인 금융/ERP 서비스에 적합합니다. 반면, DynamoDB는 초당 수만 건의 트래픽을 처리해야 하는 로그 분석이나 이벤트 기반 서비스에 유리하지만, JOIN이 불가능하므로 애플리케이션 레이어에서 데이터를 재조합하는 로직이 추가되어 개발 복잡도가 상승합니다.
💡 클라우드메트릭 비평 및 인사이트
NoSQL 환경에서 멀티테넌트 구현 시 가장 흔히 저지르는 실수는 Partition Key 설계 오류입니다. 특정 테넌트의 트래픽이 몰리는 핫 파티션(Hot Partition) 현상은 서비스 전체의 성능 저하(Noisy Neighbor)로 이어지므로, 반드시 데이터 분포를 예측할 수 있는 복합 키(Composite Key) 설계를 선행해야 합니다.
3.2 도입 시 고려사항과 향후 전망: AI 시대의 멀티테넌트
앞으로의 멀티테넌트 아키텍처는 단순히 데이터를 격리하는 것을 넘어, LLM(Large Language Model) 및 RAG(Retrieval-Augmented Generation) 기술과의 결합을 준비해야 합니다. 최근에는 LangChain 등을 활용하여 각 테넌트별로 독립적인 Vector Database 인덱스를 구축하고, 테넌트별 Embedding 모델을 관리하는 기술이 부상하고 있습니다.
이 과정에서 가장 큰 위협은 프롬프트 인젝션(Prompt Injection)을 통한 테넌트 간 데이터 침범입니다. 공격자가 프롬프트를 조작하여 다른 테넌트의 컨텍스트를 탈취하려 할 때, 이를 방어하기 위해서는 아키텍처 수준에서의 Input Sanitization과 Context Isolation이 필수적입니다. 따라서 차세대 SaaS 아키텍트는 데이터 저장의 격리뿐만 아니라, AI 에이전트가 참조하는 Context Window 내에서의 보안 경계 설정까지 설계 범위에 포함해야 합니다.
결론적으로, 성공적인 멀티테넌트 아키텍처는 보안(Security)과 비용(Cost)이라는 두 축 사이에서 끊임없이 움직이는 트레이드오프(Trade-off)의 예술입니다. AWS Cost Explorer를 통한 지속적인 비용 분석과 AWS Trusted Advisor를 통한 보안 점검을 아키텍처 설계의 일부로 내재화하는 프로세스가 반드시 수반되어야 합니다.
결론: 비용 효율성과 보안성의 균형 전략
대규모 B2B SaaS 플랫폼의 멀티테넌트 아키텍처 설계는 데이터 격리와 비용 효율성 사이의 균형이 핵심적입니다.
- 논리적 격리와 컴플라이언스: AWS Organizations와 IAM Policy를 이용한 논리적 격리는 보안 컴플라이언스 요구사항을 충족시키는 최선의 방안입니다.
- 서버리스와 데이터 모델링: DynamoDB와 AWS Lambda를 기반으로 한 서버리스 아키텍처는 확장성 면에서 우수하지만, 복합 키 등 데이터 모델링에 대한 깊은 이해가 필요합니다.
- 식별자 최적화: 테넌트 식별자 관리 시 단순 순차 정수 대신 Snowflake ID나 UUID를 사용하여 성능 저하와 보안 위협을 방지해야 합니다.
실무에서 멀티테넌트 아키텍처를 설계할 때는 AWS Cost Explorer를 활용한 비용 분석과 AWS Trusted Advisor를 이용한 보안 점검을 정기적으로 수행하는 것이 중요합니다. 특히 테넌트 오염 발생 시 즉각적인 대응 프로토콜을 마련하고, Row-Level Security 정책의 정기적 검토를 통해 데이터 무결성을 유지해야 합니다. 이러한 전략을 지속적으로 적용할 때만 진정한 엔터프라이즈급 보안 아키텍처를 구현할 수 있습니다.
참고 문헌 및 출처
- AWS Architecture Blog: "Designing a Secure and Cost-Effective Multi-Tenant Architecture"
- SaaS 애플리케이션을 위한 물리적/논리적 데이터 격리 전략 및 Best Practices.
- URL:
https://aws.amazon.com/blogs/industry/
- PostgreSQL Documentation: "Row-Level Security (RLS)"
- 데이터베이스 엔진 레벨에서의 세션 기반 데이터 접근 제어 및 격리 강제 방법론.
- URL:
https://www.postgresql.org/docs/current/ddl-rls.html
- Amazon DynamoDB Developer Guide: "Best Practices for Designing and Using Partition Keys Effectively"
- 멀티테넌트 환경에서의 Hot Partition 방지 및 데이터 분산 최적화 전략.
- URL:
https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/
- Redis Documentation: "Redis Cluster Mode"
- 대규모 분산 환경에서의 테넌트 식별자 캐싱 및 메모리 관리 최적화 기법.
- URL:
https://redis.io/docs/latest/operate/
'테크 인사이트' 카테고리의 다른 글
| 아파치 카프카(Apache Kafka) 파티션 최적화: 실시간 스트리밍 아키텍처 가이드 (0) | 2026.06.11 |
|---|---|
| 엔터프라이즈 API 게이트웨이: 분산 시스템 트래픽 제어 및 보안 강화 전략 (0) | 2026.06.10 |
| 엔터프라이즈 CI/CD 파이프라인: DevSecOps 통합 및 자동화 보안 전략 (0) | 2026.06.08 |
| Kubernetes(K8s) 대규모 컨테이너 오케스트레이션: GitOps 자동화 및 운영 노하우 (0) | 2026.06.07 |
| 클라우드 네이티브 MSA 전환: 마이크로서비스 장단점 및 아키텍처 설계 가이드 (0) | 2026.06.06 |



