복잡한 교통망 인프라에서 300ms 지연을 해결하는 공간 데이터베이스 최적화 전략. PostGIS 및 GiST 인덱싱을 활용한 지하철 노선 검색 성능 극대화 가이드.
서론: 대규모 모빌리티 인프라의 경로 탐색 지연(Latency) 문제
글로벌 모빌리티 서비스로 확장을 준비하던 대형 교통 플랫폼 기업 'M'사의 전략 회의실은 긴장감에 휩싸였습니다. 유럽 시장 진출을 위한 핵심 과제인 데이터 주권(Data Sovereignty) 확보와 현지 규제 준수보다 더 시급한 문제는, 급증하는 사용자 트래픽을 감당하지 못해 발생하는 경로 탐색 지연(Latency) 문제였기 때문입니다. 서울과 런던, 뉴욕처럼 복잡한 지하철망을 보유한 도시에서, 수천 개의 역과 노선 구간을 연결하는 쿼리가 500밀리초(ms)를 넘어서는 순간 서비스의 신뢰도는 급격히 하락합니다.
단순히 지도 위에 역 이름을 표시하는 수준을 넘어, 실시간 열차 지연 정보와 환승 최적화 경로를 계산해야 하는 현대의 위치 기반 서비스(LBS)는 단순한 데이터 조회를 넘어선 고도의 알고리즘 설계와 공간 데이터베이스(Spatial Database) 최적화 역량을 요구합니다. 특히 지하철 노선과 같이 정점(Vertex)과 간선(Edge)이 복잡하게 얽힌 네트워크 그래프(Network Graph) 구조에서는 전통적인 인덱싱 방식만으로는 성능 병목을 해결할 수 없습니다. 본 칼럼에서는 대규모 인프라 기반의 위치 검색 시스템을 구축하기 위한 핵심 아키텍처와 성능 극대화를 위한 엔지니어링 전략을 심층적으로 분석합니다.
1. 지하철 노선도 모델링과 공간 데이터베이스 관리 철학
지하철 네트워크를 디지털 환경으로 이식할 때 가장 먼저 직면하는 설계 과제는 인프라의 물리적 특성을 어떻게 논리적 그래프 구조로 추상화할 것인가입니다. 효율적인 검색을 위해서는 지하철 역(Station)을 정점(Vertex)으로, 역과 역 사이의 궤도를 간선(Edge)으로 정의하는 철도 그래프(Railway Graph) 모델링이 선행되어야 합니다. 이때 단순한 좌표값의 나열을 넘어, 각 간선에는 이동 시간, 노선 유형, 역 간 거리와 같은 다차원적인 가중치(Weight)가 포함되어야 합니다.
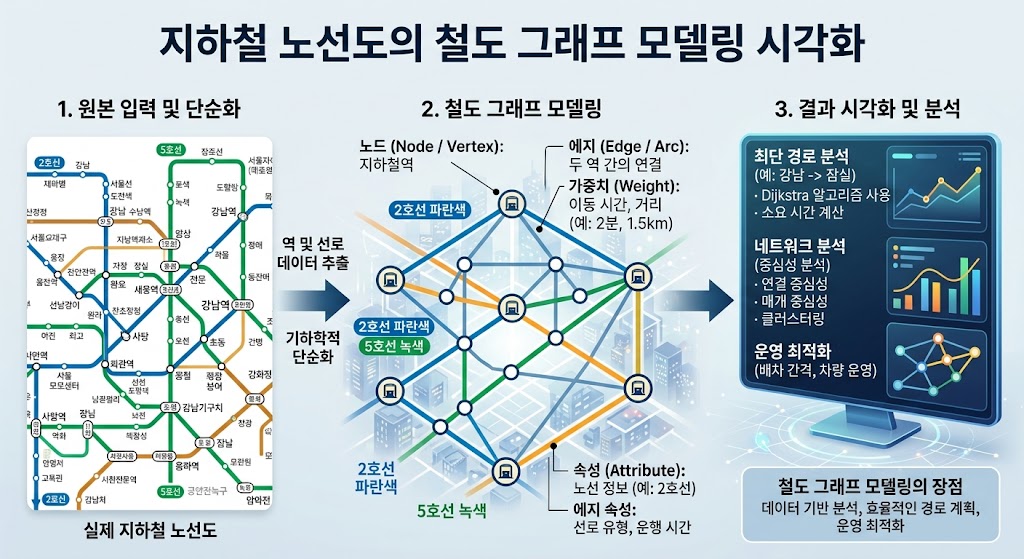
이러한 그래프 데이터를 저장하고 관리하는 데 있어 PostGIS(PostgreSQL Spatial Extension)는 표준적인 선택지입니다. PostGIS는 단순한 공간 쿼리를 넘어, 선형 참조 시스템(Linear Referencing System)을 통해 궤도 상의 특정 위치를 추적하는 데 탁월한 기능을 제공합니다.
하지만 문제는 지하철 노선처럼 데이터가 중첩되고 교차하는 구간에서 발생합니다. 2차원 평면상의 R-tree 인덱싱은 최소 경계 사각형(Minimum Bounding Box, MBR)을 기반으로 데이터를 그룹화하는데, 지하철 노선이 밀집된 도심 지역에서는 이 MBR들이 서로 과도하게 겹치게 되어 검색 범위가 불필요하게 넓어지는 현상이 발생합니다.
💡 클라우드메트릭 비평 및 인사이트
R-tree 구조는 공간적 인접성을 파악하는 데 효율적이지만, 지하철 노선이 수직/수평으로 밀집된 도심 구간에서는 MBR의 중첩(Overlap)으로 인해 인덱스 스캔 성능이 급격히 저하됩니다. 따라서 단순 R-tree를 넘어, 공간적 특성을 반영한 GiST(Generalized Search Tree)를 활용하여 중첩된 경계를 보다 정교하게 분할하는 전략이 필수적입니다.
엔지니어는 GiST(Generalized Search Tree) 인덱스를 적용하여, 공간 객체의 경계를 계층적으로 관리함으로써 검색 범위를 최소화해야 합니다. 이는 쿼리 실행 계획(Execution Plan) 단계에서 불필요한 데이터 페이지 로드를 방지하며, 복잡한 교차 구간에서의 검색 성능을 비약적으로 향상시키는 핵심 요소가 됩니다. GiST는 복잡한 지하철 노선처럼 불규칙한 형태가 섞여 있는 데이터셋에서 압도적인 우위를 점하며, 이는 공간 데이터 관리의 물리적 한계를 논리적으로 해결하는 중요한 기법입니다.
2. 경로 탐색 알고리즘의 가중치 최적화와 실시간 데이터 처리 전략
지하철 기반 위치 서비스의 핵심 로직은 목적지까지의 최단 경로를 찾는 경로 탐색 알고리즘(Pathfinding Algorithm)에 있습니다. 가장 널리 사용되는 Dijkstra 알고리즘은 모든 경로를 탐색하여 최단 거리를 보장하지만, 노드가 수만 개에 달하는 대규모 네트워크에서는 연산 비용이 기하급수적으로 증가합니다. 이를 해결하기 위해 목적지까지의 휴리스틱(Heuristic) 함수를 도입한 A* 알고리즘이 실무에서 주로 채택됩니다.

A* 알고리즘의 성능은 휴리스틱 함수의 정확도에 의존합니다. 단순히 두 좌표 사이의 직선거리를 사용하는 유클리디안 거리(Euclidean Distance) 방식은 지하철 노선과 같은 네트워크 구조에서는 오차가 발생하기 쉽습니다. 따라서 실제 구현 시에는 지구 곡률을 고려한 하버사인 공식(Haversine Formula)을 기반으로 하되, 지하철 노선의 실제 궤도 곡률과 환승 대기 시간을 가중치로 포함하는 정교한 비용 함수(Cost Function) 설계가 필요합니다.
실시간성 확보를 위한 데이터 레이어 설계 역시 중요합니다. 모든 쿼리를 물리적 디스크에 저장된 DB로 보내는 것은 자살 행위와 같습니다. 엔지니어는 다음과 같은 3단계 계층화 전략을 구축해야 합니다.
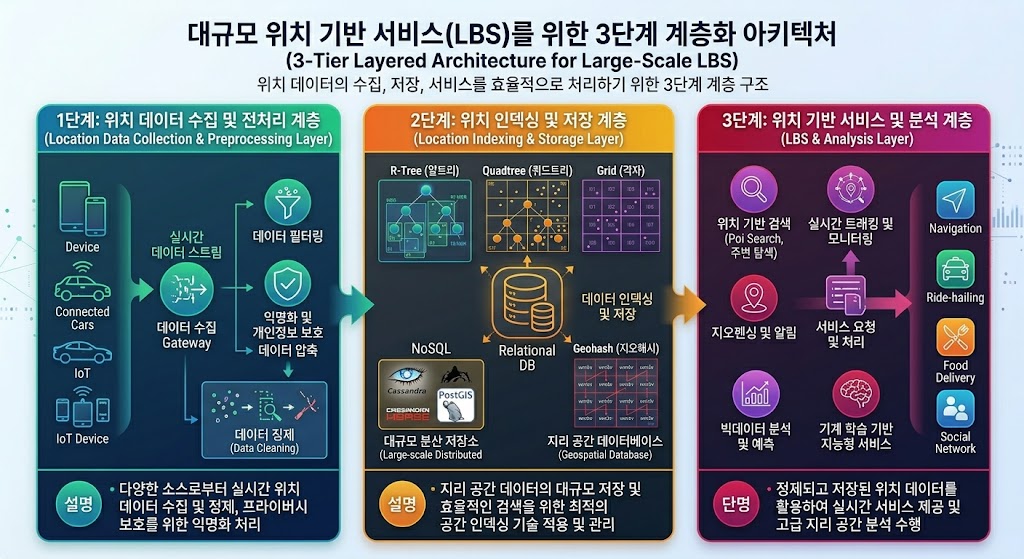
- Redis를 활용한 Hot-Key 캐싱: 강남, 홍대, 서울역과 같이 이용객이 집중되는 허브 역(Hub Station)의 구간 이동 시간 데이터는 메모리 내에 캐싱하여 읽기 성능을 밀리초(ms) 단위로 유지해야 합니다. 이때 캐시 무효화(Cache Invalidation) 전략으로 TTL(Time-to-Live)을 짧게 설정하여 실시간 지연 정보 반영을 도모합니다.
- Kafka를 이용한 이벤트 스트리밍: 열차의 실시간 위치 및 지연 정보는 Kafka 프로듀서(Producer)를 통해 유입되며, 이를 컨슈머(Consumer)가 처리하여 실시간으로 가중치 테이블을 업데이트합니다. 이는 데이터베이스에 가해지는 쓰기 부하를 분산시키는 핵심적인 역할(Event Sourcing)을 수행합니다.
- PostGIS를 통한 영구 저장 및 복잡 쿼리 처리: 정적인 노선 정보와 역사(History) 데이터는 강력한 정규화와 공간 인덱싱이 적용된 PostGIS에 저장하여 데이터의 무결성을 보장합니다.
> **💡 클라우드메트릭 비평 및 인사이트** > 실시간 데이터 처리에서 가장 간과하기 쉬운 지점은 캐시 무효화(Cache Invalidation)의 타이밍입니다. Kafka를 통한 빠른 업데이트가 이루어지더라도, Redis의 캐시가 적시에 만료되지 않으면 사용자에게는 '과거의 지연 정보'가 전달되는 치명적인 오류가 발생할 수 있으므로 이벤트 기반의 정교한 캐시 갱신 로직을 반드시 병행 설계해야 합니다.
## 3\. 차세대 기술 도입을 위한 성능 비교 및 보안 아키텍처 고려사항
기술적 성숙도가 높아짐에 따라, 기존의 관계형 데이터베이스(RDBMS) 중심 구조에서 벗어나 클라우드 네이티브(Cloud-native) 및 인공지능(AI) 기반의 대안 기술 검토가 활발히 이루어지고 있습니다. 특히 글로벌 확장을 목표로 하는 서비스라면 AWS RDS와 같은 단일 리전 기반 서비스와 Google Cloud Spanner와 같은 글로벌 분산 데이터베이스 사이의 트레이드오프(Trade-off)를 명확히 이해해야 합니다.
Google Cloud Spanner는 강력한 일관성(Strong Consistency)과 글로벌 스케일링을 동시에 제공하므로, 전 세계 여러 도시의 지하철 데이터를 통합 관리해야 하는 글로벌 모빌리티 플랫폼에 적합합니다. 반면 비용 효율성과 지역적 최적화가 우선인 경우에는 AWS RDS(PostgreSQL/PostGIS) 환경이 유리합니다.
| 비교 항목 | PostGIS (RDS) | Google Cloud Spanner | Graph Neural Networks (GNN) |
| --- | --- | --- | --- |
| 주요 용도 | 정밀한 공간 데이터 관리 | 글로벌 규모의 트랜잭션 처리 | 패턴 기반 경로 예측 |
| 확장성(Scalability) | 수직 확장 중심 (Vertical) | 수평 확장 중심 (Horizontal) | 모델 연산량에 의존 (GPU) |
| 데이터 모델 | Relational + Spatial | Relational (Distributed) | Graph-based Tensor |
| 주요 장점 | 성숙한 생태계, 높은 정확도 | 글로벌 일관성, 무중단 확장 | 초고속 패턴 매칭, 예측 기능 |
최근에는 Graph Neural Networks(GNN)를 활용하여 과거의 교통 패턴을 학습하고, 향후 발생할 지연 상황을 예측하는 연구가 실무에 적용되기 시작했습니다. GNN은 정형화된 알고리즘보다 훨씬 빠르게 복잡한 네트워크의 상태를 파악할 수 있지만, 높은 연산 비용과 하드웨어 요구 사항이라는 비용적 장벽이 존재합니다.
마지막으로, 위치 데이터 처리 시 반드시 고려해야 할 것은 GDPR과 같은 개인정보 보호 규정입니다. 사용자의 이동 경로(Trajectory)는 매우 민감한 개인 식별 정보(PII)를 포함하고 있습니다. 따라서 데이터를 저장할 때 가명화(Pseudonymization) 기술을 적용하고, 특정 위치 정보의 정밀도를 의도적으로 낮추는 차등 프라이버시(Differential Privacy) 기법의 도입을 검토해야 합니다.
💡 클라우드메트릭 비평 및 인사이트
GNN과 같은 최신 AI 기술 도입은 응답 속도를 혁신적으로 개선할 수 있으나, 인프라 비용(Cloud Cost) 급증을 초래할 수 있습니다. 따라서 모든 쿼리에 AI를 적용하기보다는 단순 경로 탐색은 기존 A* 알고리즘으로 수행하고, 혼잡도가 극심한 구간의 예측에만 선별적으로 적용하는 하이브리드 전략이 경제적 관점에서 가장 타당합니다.
결론: 지속 가능한 교통 인프라 아키텍처를 향하여
지하철 노선과 같은 복잡한 인프라 기반의 위치 검색 시스템은 단순히 알고리즘의 효율성만을 다루는 영역이 아닙니다. 이는 공간 데이터베이스의 물리적 저장 구조, 실시간 스트리밍을 통한 데이터 동기화, 그리고 글로벌 확장을 고려한 클라우드 인프라 설계가 유기적으로 결합되어야 하는 고난도의 엔지니어링 과제입니다.
성공적인 시스템 구축을 위한 실무 체크리스트를 제안합니다.
- 인덱스 최적화: 단순 R-tree를 넘어 GiST를 활용하여 공간 객체의 중첩 문제를 해결했는가?
- 계층적 캐싱: Redis를 통해 빈번한 쿼리에 대한 응답 속도를 밀리초 단위로 보장하고 있는가?
- 데이터 정합성: Kafka를 통한 실시간 업데이트와 캐시 무효화 로직이 일관되게 동작하는가?
- 규제 준수: 위치 정보 가명화 및 보안 아키텍처가 GDPR 등 글로벌 컴플라이언스를 충족하는가?
미래의 위치 기반 서비스는 자율주행 셔틀, 퍼스널 모빌리티(PM), 그리고 다중 모드 교통(Multi-modal Transport) 체계와 결합되어 더욱 복잡한 네트워크를 형성할 것입니다. 이러한 변화에 대응하기 위해서는 고정된 아키텍처가 아닌, 데이터의 흐름과 확장성을 유연하게 수용할 수 있는 탄력적인 인프라 설계 역량이 무엇보다 중요합니다.
참고 문헌 및 출처 (References)
- PostGIS Documentation: "PostGIS Special Functions Index"
- R-tree 및 GiST 인덱스 최적화 및 공간 쿼리 성능 개선 가이드.
- URL:
[https://postgis.net/documentation/]
- pgRouting Official Repository: "Graph Algorithms in PostGIS"
- A* 알고리즘 및 다익스트라(Dijkstra)를 활용한 공간 데이터베이스 내 경로 탐색 구현체.
- URL:
[https://github.com/pgrouting/pgrouting]
- Google Cloud Spanner: "TrueTime and External Consistency"
- 글로벌 분산 데이터베이스 아키텍처 및 강력한 일관성 설계 원리.
- URL:
[https://cloud.google.com/spanner/docs/true-time-external-consistency]
- arXiv: "Graph Neural Networks for Traffic Prediction"
- 교통량 예측 및 네트워크 구조 학습을 위한 GNN 알고리즘 연구 논문.
- URL:
[https://arxiv.org/abs/1903.04681]
'테크 인사이트' 카테고리의 다른 글
| 데이터 파편화 해결과 조직 매핑: 프로덕트·엔지니어링·그로스 협업 아키텍처 (0) | 2026.06.03 |
|---|---|
| B2C 추천 시스템 설계: 실시간 로그 파이프라인과 AI 최적화 전략 (0) | 2026.06.03 |
| 대규모 3D 렌더링 파이프라인 최적화: PBR 표준화 및 절차적 텍스처링 설계 (0) | 2026.06.02 |
| AI 캐릭터 다각도 일관성 유지: ControlNet, LoRA, IP-Adapter 최적화 전략 (0) | 2026.06.01 |
| 글로벌 LBS 앱 로컬라이제이션: 에지 컴퓨팅 및 데이터 주권 아키텍처 설계 (0) | 2026.05.31 |



