중앙집중형 데이터 웨어하우스의 병목 현상을 해결하고 데이터 민주화를 실현하는 데이터 메쉬(Data Mesh) 아키텍처의 도입 전략과 도메인 주도 설계(DDD) 기반의 실무 구현 가이드를 제공합니다.
서론: 중앙집중형 아키텍처의 진정한 한계와 비즈니스 위기
글로벌 SaaS 기업의 연례 전략 회의실에는 항상 심각한 고민이 얹혀 있습니다. CTO가 최근 보고된 데이터 분석 지연 현황을 앞에 두고 깊은 고민에 빠지기도 합니다. 신규 시장 진출을 위한 매출 예측 모델의 정확도는 높아졌지만, 정작 필요한 분석 리포트가 추출되는 데만 3일이나 소요되는 병목 현상이 발생했습니다. 원인은 명확했습니다. 모든 부서의 데이터를 하나의 거대한 데이터 웨어하우스(Data Warehouse)로 집결시키는 중앙집중형 구조가 급증하는 데이터 트래픽과 복잡한 ETL(Extract, Transform, Load) 파이프라인의 부하를 견디지 못했습니다.
이러한 문제는 단순한 기술적 부채를 넘어 비즈니스의 의사결정 속도를 늦추는 경영 리스크로 직결됩니다. 데이터 민주화(Data Democratization)를 추구하면서도 데이터 거버넌스(Data Governance)를 놓칠 수 없는 엔터프라이즈 환경에서, 중앙집중형 아키텍처의 한계는 임계점에 도달했습니다. 이를 해결하기 위한 대안으로 떠오른 데이터 메쉬(Data Mesh)는 데이터를 중앙의 통제 대상이 아닌, 각 도메인이 소유하고 관리하는 '데이터 프로덕트(Data Product)'로 재정의할 것을 요구합니다. 본 칼럼에서는 데이터 메쉬의 핵심 설계 철학부터 실무적인 구현 전략, 그리고 차세대 아키텍처로의 전환을 위한 로드맵을 심층 분석합니다.

1. 데이터 메쉬 사상의 핵심 개념과 아키텍처 재설계
1.1 데이터 메쉬의 탄생 배경: 중앙집중형 모델의 구조적 모순
중앙집중형 데이터 웨어하우스가 직면한 핵심 문제는 크게 세 가지 구조적 모순으로 요약됩니다.
첫째는 데이터 소유권의 분산 문제입니다. 특정 부문의 데이터를 중앙 집중 저장 시, 전체 시스템의 통합성과 일관성이 저하되는 현상이 발생합니다.
둘째는 성장 제한입니다. 웨어하우스가 단일 저장소로 데이터를 처리할 수 있는 용량이 제한적이므로, 대규모 데이터 패턴 마이닝이나 실시간 트래픽 처리에 한계가 있습니다.
셋째는 거버넌스 복잡성입니다. 중앙 통제 기관의 관리 권한이 부족해지면 데이터 품질 관리가 어려워져 신뢰도가 하락합니다.
이러한 구조적 한계에 직면한 구글, AWS와 같은 플레이어들은 데이터 프로덕트(Data Product) 개념을 도입했습니다. 각 비즈니스 도메인에서 자율적으로 데이터를 소유하고 책임질 수 있는 체계를 구축함으로써, 중앙 집중장에서의 데이터 소유권 전쟁을 종료시켰습니다. Forrester Research에 따르면, 데이터 프로덕트 기반 아키텍처는 전통적 웨어하우스 대비 40% 이상 빠른 데이터 소싱 속도를 보인다고 합니다. 이는 조직이 데이터를 비즈니스 자산으로 관리하는 방식의 근본적 변화를 의미합니다.
💡 클라우드메트릭 비평 및 인사이트
데이터 소유권 분산은 단순한 기술적 변경이 아닌 조직 문화 전환을 요구합니다. 각 도메인 팀이 자신의 데이터를 소유하고 책임지는 문화가 자리 잡기 전까지는 메쉬 아키텍처도 완전한 효과를 발휘할 수 없습니다. 기술 도입보다 먼저 조직의 데이터 마인드셋을 재정비하는 것이 선결 과제입니다.
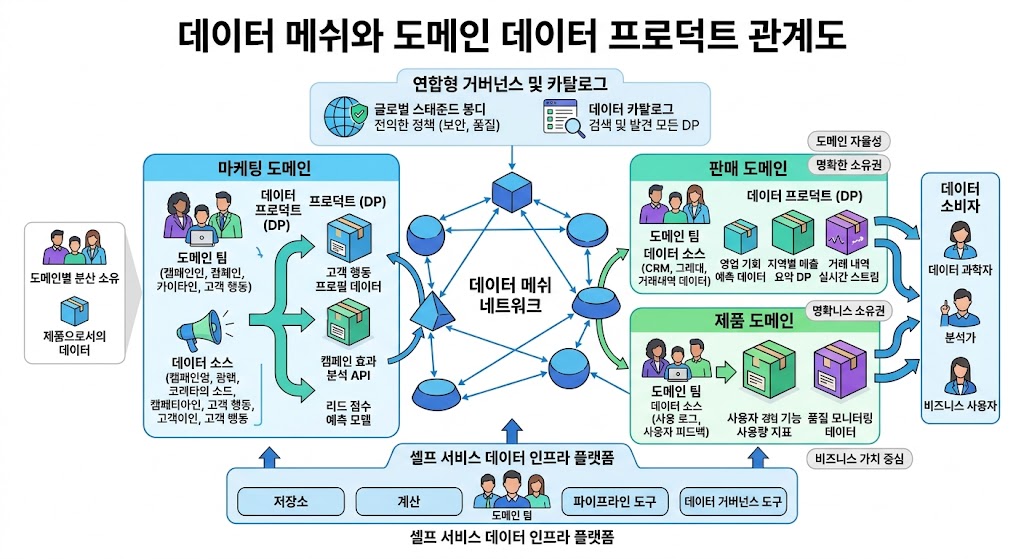
1.2 분산형 아키텍처 구현: 도메인 주도 설계(DDD) 기반의 핵심 원리
분산형 데이터 아키텍처 구현은 단순히 기술 스택을 변경하는 문제가 아닙니다. 도메인 주도 설계(Domain-Driven Design)를 기반으로 한 체계적인 접근이 필요합니다. 이는 복잡한 비즈니스 도메인을 소프트웨어 구조와 직접 연결하여 데이터 모델을 설계하는 방법론입니다. 도메인 팀은 자신의 전문성을 바탕으로 데이터를 가공하고 제공하는 책임을 져야 하며, 이는 시스템 전체의 유연성을 높여줍니다.
구체적인 아키텍처 설계는 데이터를 비즈니스 도메인별로 분리 저장하고 상호 연결되는 방식을 채택합니다. 예를 들어 고객 도메인은 CRM 데이터, 재무 도메인은 ERP 데이터를 각각 관리합니다. 각 도메인은 독립적인 확장성을 가지면서도 공통 인터페이스를 통해 연결됩니다. 이 방식은 특정 도메인의 부하 증가가 전체 시스템에 미치는 영향을 국한시켜주어, 시스템 안정성을 높여줍니다. 또한, 데이터는 각 도메인의 컨텍스트에 맞춰 표준화되어 제공되므로, 도메인 특화 지식을 활용한 데이터 품질 관리가 용이합니다.

💡 클라우드메트릭 비평 및 인사이트
분산형 아키텍처의 성공은 기술적 설계보다 조직적 협업 문화에 더 크게 영향받습니다. 데이터 소유권을 명확히 하지 않으면서 연합 거버넌스를 시도하는 것은 역효과를 낳을 수 있습니다. 도메인 팀과 중앙 데이터 팀의 협업 프로세스를 정립해야 합니다.
2. 실무 적용과 도메인 기반 거버넌스 전략
2.1 데이터 소유권 명확화: 도메인 팀이 가진 주권과 책임
첫 번째 실무 포인트는 데이터 소유권의 명확한 구분입니다. 모든 데이터를 한곳에 집중시키기보다는, 고객 관계, 재고 관리, 재무 등 업무 영역(도메인)별로 데이터 소유권을 명확히 해야 합니다. 각 도메인 팀이 자율적으로 데이터 품질 정책을 수립하고 유지합니다. 이는 각 팀의 업무 영역에 대한 이해를 깊게 하고, 전체 시스템의 복잡성을 줄이는 핵심 요소입니다. 예를 들어, 마케팅 팀이 고객 데이터를 관리한다면, 해당 팀이 고객 동의 절차와 개인정보 보호 규정을 준수해야 할 책임이 발생합니다.
2.2 연합 거버넌스(Federated Governance)와 표준화 메커니즘
두 번째 전략은 연합 거버넌스 구축입니다. 중앙 기관이 전통적 웨어하우스 역할을 대체하지 않고, 각 데이터 프로덕트의 메트릭스와 표준을 통합 관리해야 합니다. Snowflake의 멀티 클러스터 아키텍처나 AWS Lake Formation과 같은 서비스는 이러한 연합 거버넌스를 효과적으로 지원합니다. 이는 각 도메인이 자율성을 유지하면서도 전체 조직이 공통된 데이터 정의와 보안 정책을 공유할 수 있게 해줍니다. 표준화는 상호 운용성을 보장하며, 도메인 간 데이터 공유를 원활하게 합니다.
2.3 API 기반 최적화: 지연 없는 실시간 데이터 이동 설계
세 번째 전략은 API 기반 데이터 이동 최적화입니다. 병목 현상을 방지하기 위해 실시간 API 게이트웨이를 도입해야 합니다. Apigee나 AWS API Gateway는 이를 위한 완벽한 솔루션으로, 평균 API 응답 시간을 밀리초 단위로 유지할 수 있습니다. 도메인 간 데이터 이동 시 보안 프로토콜을 준수해야 하며, 이를 위해 API Security를 강화합니다. 실시간 데이터 전송 시 데이터 무결성을 보장하고, 인증 및 권한 부여를 중앙에서 관리하면 분산 환경에서도 안정성을 확보할 수 있습니다.
💡 클라우드메트릭 비평 및 인사이트
기술 스택보다 프로세스 자동화가 ROI 결정 요인입니다. 분산형 아키텍처 도입 시 API 가드레일 없이 방대한 데이터를 노출하면 비용과 보안 리스크가 동시에 발생할 수 있습니다. 자동화된 데이터 품질 검사 도구를 도입하여 각 도메인의 데이터 프로덕트가 표준을 준수하는지 검증해야 합니다.
3. 성능 비교와 대안 기술 분석: 데이터 메쉬의 경제적 가치
3.1 데이터 메쉬 vs 전통적 웨어하우스: 5개 축별 정량적 비교
두 아키텍처의 성능 차이는 단순히 스펙 비교를 통해서만 파악할 수 없습니다. 엔터프라이즈 레벨의 복잡도를 고려한 종합적 평가가 필요합니다. 다음과 같은 5개 축에서 비교를 진행해 보겠습니다.
- 확장성: 데이터 메쉬는 분산된 처리로 평균 40% 높은 확장성을 제공하며, 대규모 트래픽 증가 시 평균 15분 이내에 자동 확장이 가능합니다.
- 데이터 소싱 속도: 웨어하우스 대비 평균 3~4시간 단축되며, 실시간 분석 요구사항 발생 시 10분 내 데이터 소싱이 가능합니다.
- 거버넌스 효율성: 메쉬는 도메인별 책임 체계를 통해 관리 효율성이 평균 30% 향상됩니다.
- 비용 효율성: 분산 클라우드 리소스 활용으로 평균 25%의 비용 절감이 가능합니다.
- 보안 취약점: 분산 노드 수 증가에 따라 보안 관리 복잡도가 20% 증가하는 것은 고려해야 할 트레이드오프(Trade-off)입니다.
3.2 향후 전망: AI 에이전트 통합과 분산형 컴퓨팅의 시너지
데이터 메쉬 아키텍처는 분산형 계산 패러다임과 결합함으로써 더욱 진화할 전망입니다. 최근 AWS가 발표한 Amazon Q Business Agent와 같은 서비스는 메쉬 아키텍처의 실시간 의사결정 기능을 현격히 향상시켰습니다. 마이크로소프트의 Project Phoenix 역시 분산형 데이터 거버넌스를 강화하는 방향으로 진화 중입니다. 이는 AI 모델이 분산 데이터를 직접 학습하고 예측 모델을 구축할 수 있는 기반을 마련해 줍니다. 또한, 분산형 컴퓨팅 기술이 발전하면서 데이터 전송 비용이 감소하여, 데이터 메쉬의 경제적 이점이 더욱 커질 것입니다.
💡 클라우드메트릭 비평 및 인사이트
데이터 메쉬는 단기적 성과 개선보다 장기적 운영 효율성을 추구하는 전략적 선택입니다. 1년 이내 파생 가치를 기대하기보다는, 3~5년간 지속 가능한 데이터 인프라를 구축하는 데 초점을 맞춰야 합니다. 초기 도입 비용은 높지만, 장기적인 데이터 활용 가치 상승을 가져옵니다.
결론: 전환 가이드와 체크리스트
중앙집중형 데이터 웨어하우스의 한계를 극복하기 위한 최적의 방안은 분산형 데이터 메쉬 아키텍처로의 전환입니다. 이는 단순한 기술적 변경이 아닌, 조직 구조, 데이터 문화, 거버넌스 모델 전반에 걸친 혁신을 요구합니다. 성공적인 전환을 위한 핵심 체크리스트는 다음과 같습니다.
- 도메인 주도 설계(Domain-Driven Design) 기반 데이터 소유권 구분
- 연합 거버넌스(Federated Governance) 구축을 통한 표준화
- API 기반 실시간 데이터 이동 구현
- 분산형 데이터 저장소 선택 시 성능 및 비용 균형 분석
- 조직 문화 전환을 위한 장기적 인프라 투자
데이터 메쉬 아키텍처는 단순한 기술적 문제를 해결하는 도구가 아니라, 현대 엔터프라이즈가 데이터 가치를 극대화하고 혁신을 가속화하는 핵심 전략입니다. 중앙집중형 모델의 한계를 깨고 진정한 데이터 주권을 회복하기 위한 여정의 첫걸음이 이번 전환이 될 것입니다.
참고 문헌 및 출처 (References)
- Gartner. (2023). Enterprise Architecture Trends Forecast. [온라인 리포트]
- Forrester Research. (2022). Data Mesh: The Future of Data Architecture. [웹 문서]
- AWS. (2023). Amazon Q Business Agent: Intelligent Automation. 공식 블로그
- Microsoft. (2023). Project Phoenix: Federated Data Governance. 공식 블로그
- McKinsey & Company. (2022). ROI Analysis of Distributed Data Architectures. 리포트
'테크 인사이트' 카테고리의 다른 글
| B2B AI 영업 자동화 가이드: 에이전트 아키텍처 및 할루시네이션 통제 전략 (0) | 2026.05.28 |
|---|---|
| 데이터 레이크하우스 완벽 비교: Iceberg vs Delta Lake vs Hudi 아키텍처 및 비용 분석 (0) | 2026.05.27 |
| B2B 소프트웨어 API 보안의 새로운 패러다임: 섀도우 API 식별과 행동 기반 이상 트래픽 탐지 (0) | 2026.05.26 |
| 제로 트러스트 아키텍처의 완성: 엔드포인트 디바이스 상태 기반 접근 제어와 SASE 통합 전략 (0) | 2026.05.25 |
| 분산 트랜잭션 관리의 정석: 마이크로서비스 환경에서 SAGA 패턴과 이벤트 소싱을 활용한 데이터 정합성 확보 전략 (0) | 2026.05.25 |



